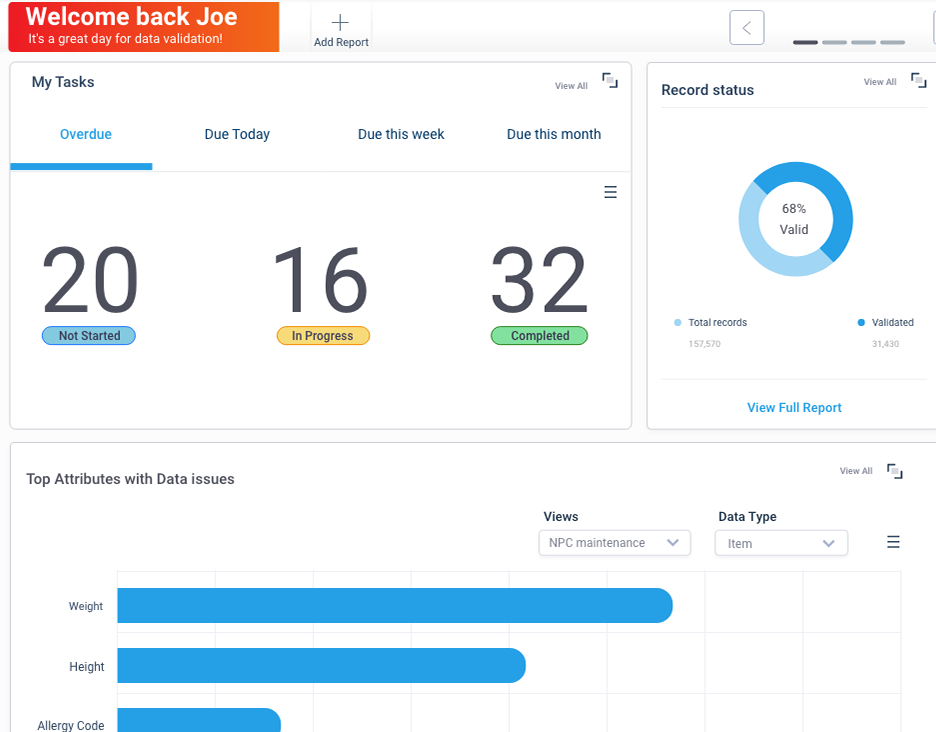
Discovery stage
We encountered many challenges within the discovery phase. The larges challenge was around customers with rules that had no documentation and were treated as a black box.
For these customers we had to go back to first principals and re assist their business requirements since even our own internal stakeholders had an unclear picture of what all the undocumented Python code was doing to each system. We went back to the basics and focussed on gathering core requirements through the following methods:
Interviews with consultants that implemented or maintained these systems.
Interviews with customers to understand their core business requirements when moving data from a source system into our system.
Analysis of s sample set of Python rules that were documented as a base line study of the core functionality.
Competitor Analysis to see what alternatives are in the market to solve the same issues
Definition stage
Problem statement
Defining a clear problem statement around business rule creation was also broken into parts. We first defined the overall problem for the business and the customer. We then drilled down into smaller issues to create problem statements for each layer of complexity. For example we found the overall problem was scalability on both the customer side and our side. It was creating a knowledge and expertise gap every time a new rule was built.
The smaller problem statements were defined for the core functions used repeatedly in each rule. For example, transformation rules for combining, splitting and applying equations to a data object had different concerns to using conditional logic for routing the flow of data.
Value Proposition
Our value proposition overall was based around creating a self serve model which would allow the company to scale much faster and empower customers to build their own business rules. It would also have the effect of lowing the skill set required to build or maintain rules since they were no longer code based.
User Journey mapping
We created a range of user journey maps since the use case was so large. The feature set was big enough to be a stand alone product and this required us to break down the roll out of the functions into small related parts. Mapping out the user journey revealed the real size of the workload. Our initial focus was on the most granular functions such as the transformation and mapping functions found in our conversion templates. We then moved to functions that managed and executed these granular tasks as a 2nd phase. These included conditional logic and the pipeline concept for managing the flow of data.
User Personas
The 2 personas below are the most impacted by usage of the new no-code rules builder. These people seem real because they actually are real. We have simply made some changes to key identity traits for the sake of privacy.


User Journey examples
Ideation stage
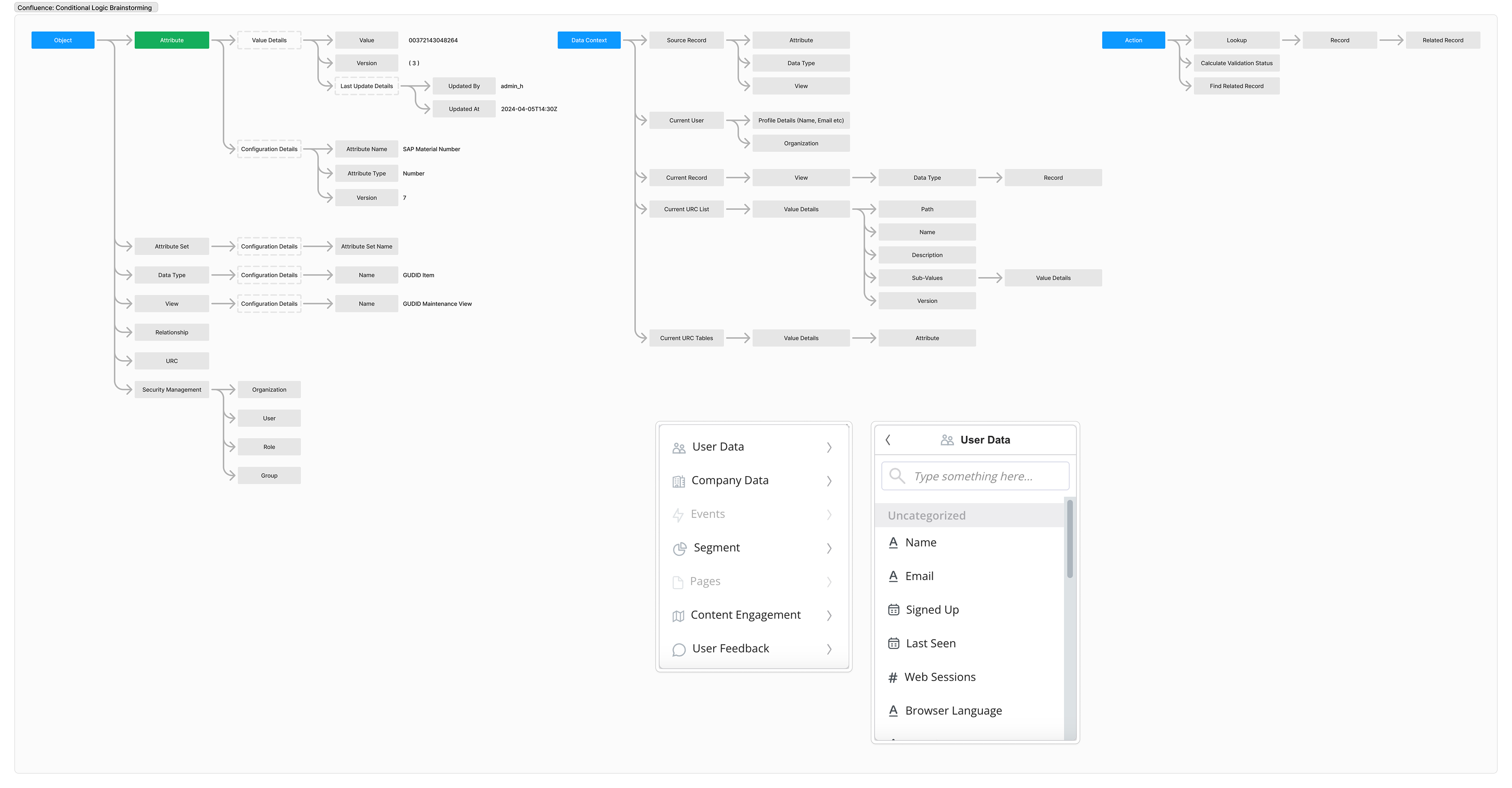
As part of our ideation we collaborated across the business to brainstorm solutions. We had a number of subject matter experts that have grappled with the problem for many years and we wanted to get their direct input on what issues they were solving with their code based rules. This allowed us to form the correct path for transforming and mapping data.

Brainstorming examples
Solution Summary
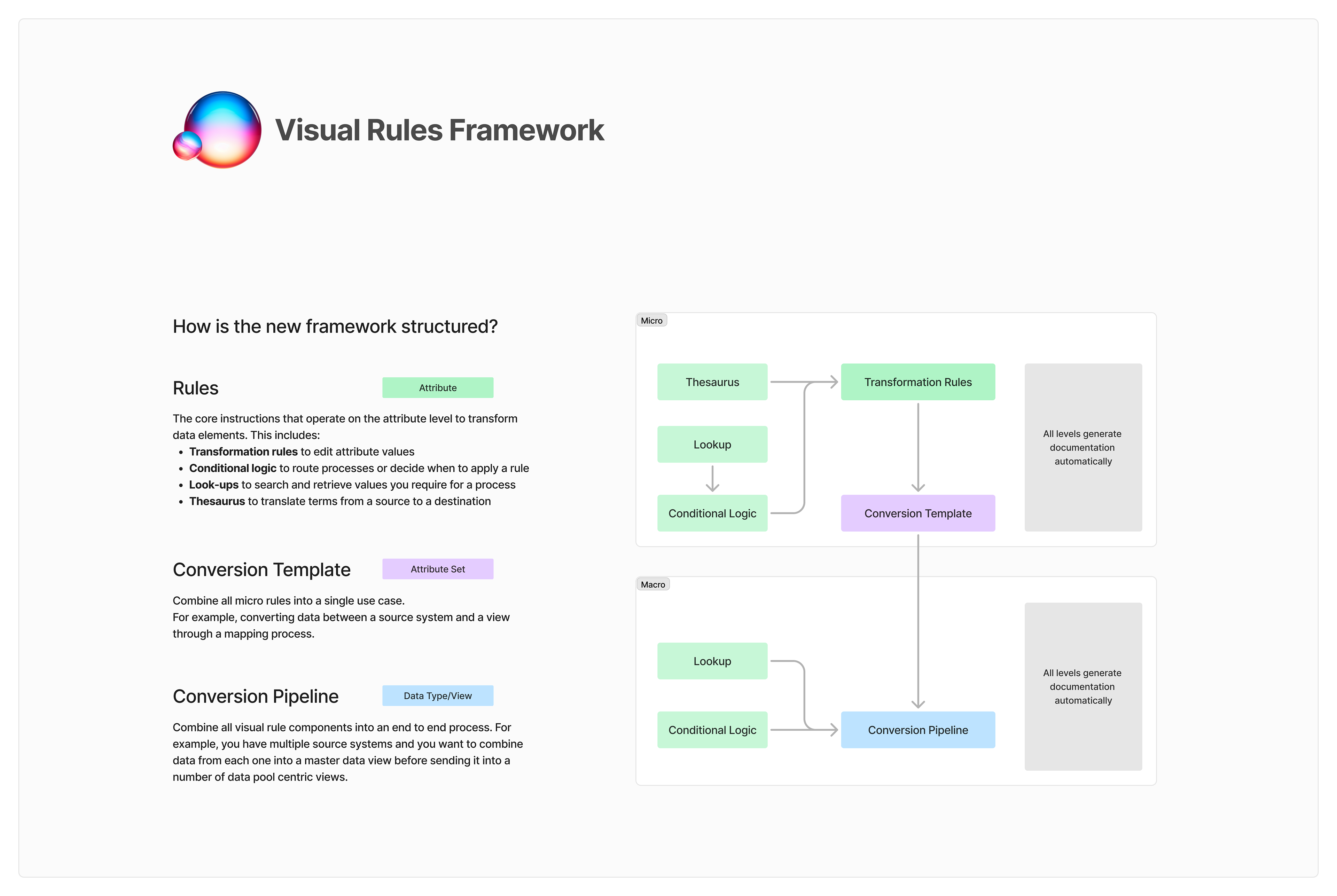
Example Solution frameworks for conditional logic.
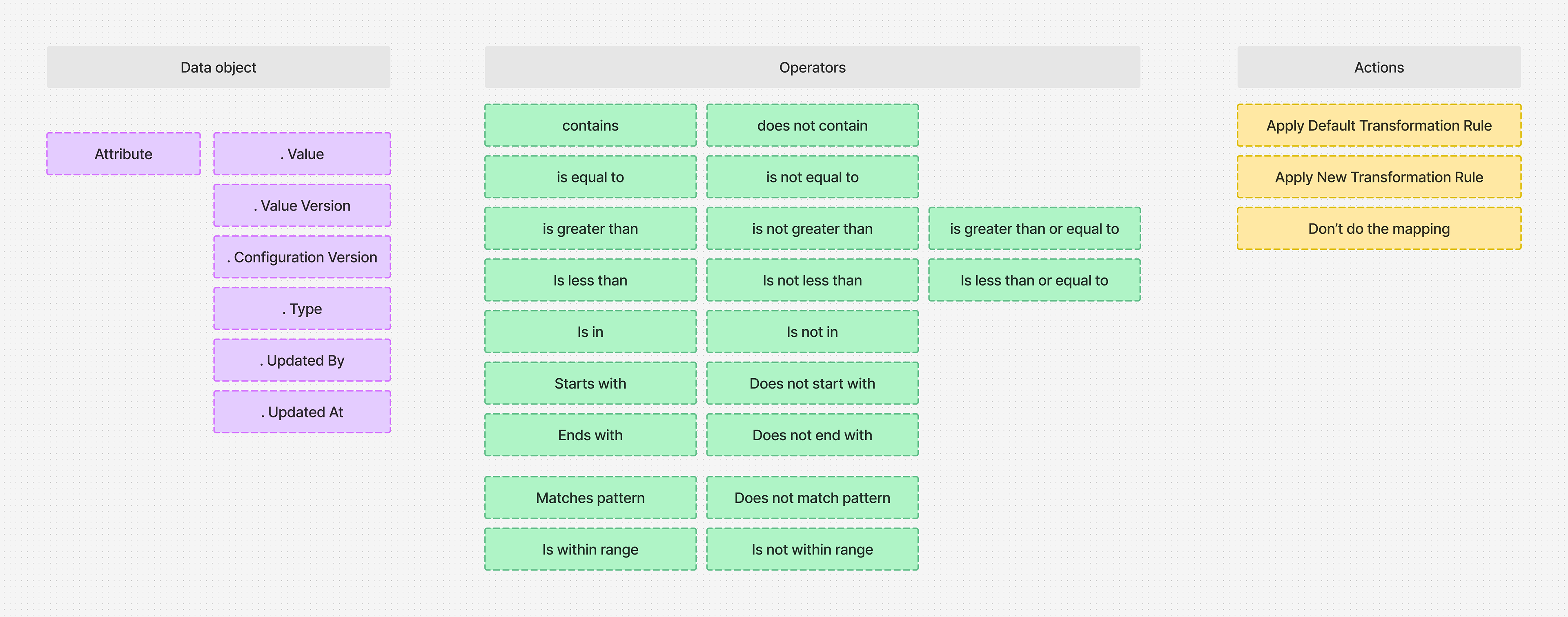
Competitor analysis
We did a full competitor analysis of similar software products in our industry and outside of our industry to find common UI patterns, terminology and hopefully uncover solutions we may have not conceptualised in our ideation.
General finding included:
Tools vary from 100% no-code to some code based rules.
Most of them use a common terminology for transforming data.
New concepts for organising the whole data flow at the macro level was uncovered.
UI patterns were similar to the core concepts we were drafting, so we were on the right track!
Design Stage
Our design outputs were broken into stages to align with release plans. In our initial release we wanted to deliver mapping, transformation and a conversion template library. In following releases we aimed to deliver conditional logic, look ups, and the pipeline concept (organising data flows at the macro level). the last release would include a validation composer which can configure business validations to check data quality.
We also developed onboarding and user guidance content to improve user adoption for all new features.
Below is the working file preview for all releases and drafts.
Testing and iterating
We are currently going through the test and iterate cycle for this functionality. We had 5 sessions with customers for general feedback and discussion on the overall approach. We have gained some really good insights from these sessions including the following:
Provide a sample data field so the rule can be tested while it's being built.
Allow for multiple suffixes or prefixes for editing data
Show where the rules are being applied in the system so the user can know exactly what data is affected if changes are applied.

Final outputs
Pipeline Concept
One space to tie all the rules and conversion together.
Initial Conversion Template and Transformation concept
The fundamental functions for converting data.
Conversion Template and Transformation iteration after collection user feedback